Getting Started with AI Guardrails
Check Point AI Guardrails screens user and external content going into LLMs and the resulting output, flagging any threats and providing real time protection for your GenAI application and users.
For an introduction to AI Guardrails and a demonstration of how it detects and prevents threats we recommend following our interactive tutorial.
Follow the steps below to detect your first prompt attack with AI Guardrails.
Create a Check Point Account
- Navigate to the AI Guardrails Dashboard
- Click on the “Create Account” button
- Enter your email address and set a secure password, or use one of the single sign on options
See AI Guardrails in action
- Navigate to the Guard playground
- In the “Select Playground” dropdown select “Chatbot Simulator”. This is a demo chatbot application that has AI Guardrails already integrated.
- Select the prompt attack example. You’ll see in the “Guard Logs” that AI Guardrails has detected an attempted malicious attack.
- This demo application is configured to just use AI Guardrails for monitoring threats by default. To see how AI Guardrails can be used to actually stop threats in real-time, navigate to the “Chatbot Configuration” and turn on “Simulate blocking”.
- Now copy and paste the previous prompt attack message and resubmit it. Note that now the demo chatbot app blocks the interaction and shows the user a crafted response when threats are detected.
- Click on the blocking response and then “Block message” to see what was screened by AI Guardrails behind the scenes.
- Now you can enter your own attacks, PII examples or content violations and see AI Guardrails detect threats and block them in real-time.
The chatbot demo app can be further configured with a custom system prompt. The AI Guardrails flagging policy can be configured to set the flagging sensitivity of the policy.
We also provide a direct Guard Tester playground, to directly screen content via AI Guardrails and see Check Point’s threat detection response.
Setting up AI Guardrails
The following diagram gives a high level overview of the process of setting up AI Guardrails and performing screening requests.
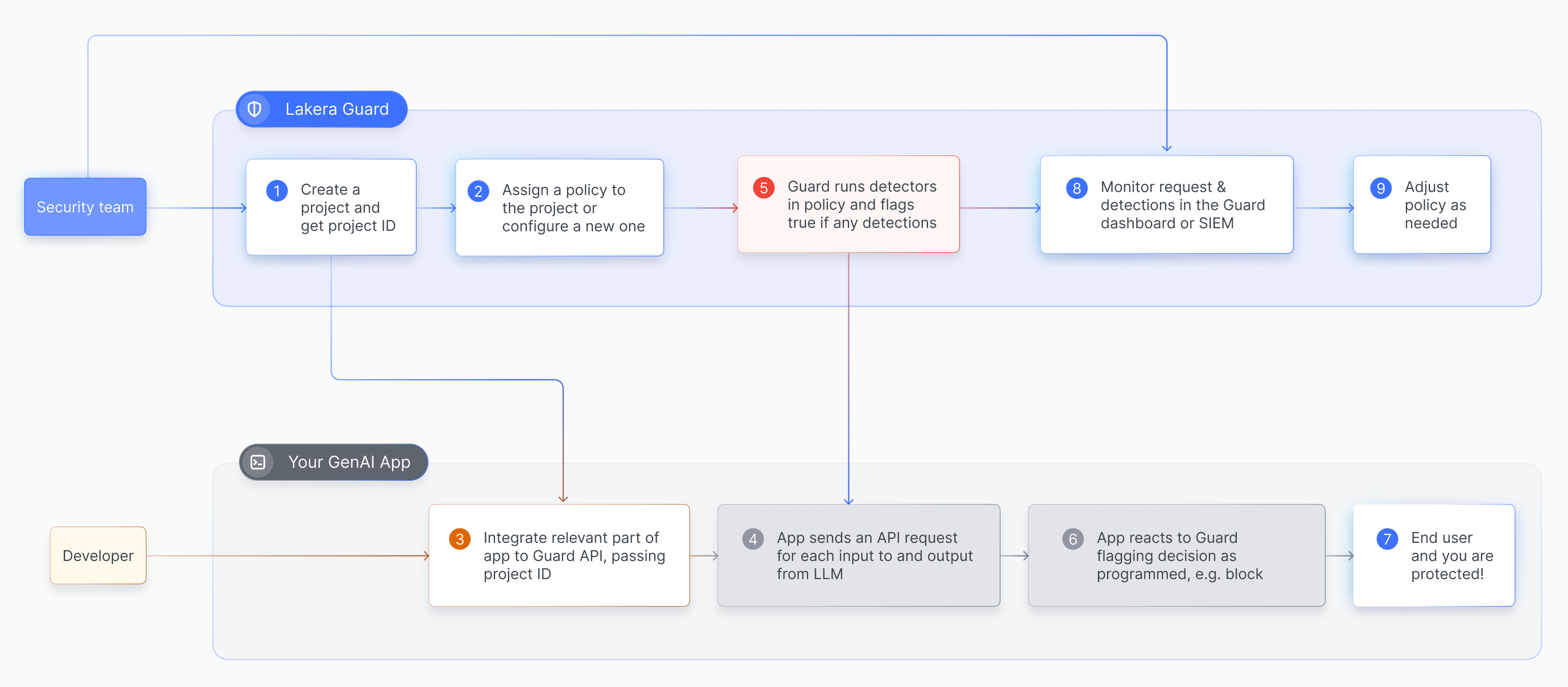
Developer quickstart
To get started using the Guard API and integrating AI Guardrails follow these steps.
Create an API Key
- Navigate to the API Access page
- Click on the ”+ Create new API key” button
- Name the key, e.g.
Guard Quickstart Key - Click the “Create” button
- Copy and save the API key securely. Please note that for security reasons once generated, it cannot be retrieved from your Check Point account
- Open a terminal session and export your key as an environment variable (replacing
<your-api-key>with your API key):
Create a project and assign a policy
- Navigate to the Projects page
- Click on “New project +” button
- Name the project, e.g.
Guard Quickstart Application - Fill in and add any custom metadata tags as relevant
- Using the “Assign a policy” dropdown, assign the Check Point recommended “Public-facing Application” policy
- Save the project and then take note of the autogenerated project ID for your project
Detect a Prompt Injection Attack
The example code below should trigger AI Guardrails’ prompt attack and unknown links detection. Replace project-XXXXXXXXXXX in the below with your project ID.
Copy and paste it into a file on your local machine and execute it from the same terminal session where you exported your API key.
Python
JavaScript
cURL
HTTPie
Other
Learn More
Integrating with the Guard API is as simple as making a POST request to the guard endpoint for each interaction with the LLM, passing the raw user and external input and the LLM output. AI Guardrails will screen the input and output contents and flag if any of the following threats are detected:
- Prompt attacks - detect prompt injections, jailbreaks or manipulation in user prompts or reference materials to stop LLM behavior being overridden
- Data leakage - prevent leakage of Personally Identifiable Information (PII) or sensitive data in user prompts or LLM outputs
- Content violation - detect offensive, hateful, sexual, violent and vulgar content in user prompts or LLM outputs
- Unknown links - detect links that are not from an allowed list of domains to prevent phishing and malicious links being shown to users
You can control and customize the defenses applied to your application by configuring policies.
Blog posts
To help you learn more about the security risks AI Guardrails protects against we recommend these blog posts:
- The ELI5 Guide to Prompt Injection: Techniques, Prevention Methods & Tools
- AI Red Teaming: Securing Unpredictable Systems
- Language Is All You Need: The Hidden AI Security Risk
- The Rise of the Internet of Agents: A New Era of Cybersecurity
Guides
For further guidance, we’ve created the following:
- Understanding Prompt Attacks: A Tactical Guide
- Building AI Security Awareness Through Red-teaming With Gandalf
- Crafting Secure System Prompts for LLM and GenAI Applications
- Prompt Injection Attacks Handbook
Other Resources
If you’re still looking for more:
- Test your prompt injection skills against Gandalf
- Download the GenAI Security Report 2024