Guard API Endpoint
The /v2/guard API endpoint is the integration point for LLM based applications using Check Point AI Guardrails. It allows you to call on all of AI Guardrails’ defenses with a single API call.
Using guard, you can submit the input and output contents of an LLM interaction to AI Guardrails. The configured detectors will screen the interaction, and a flagging response will indicate whether any threats were detected, in line with your policy.
Your application can then be programmed to take mitigating action based on the flagging response, such as blocking the interaction, warning the end user, or generating an internal security alert.
Quick Start
Before integrating, ensure you have set up a project with a suitable chosen or configured policy rather than using our default policy. The Check Point default policy is intentionally strict and will likely flag more content than appropriate for production use.
Here’s a basic example of screening an interaction:
Response:
The following diagram gives a high level overview of the process of setting up AI Guardrails and performing screening requests:
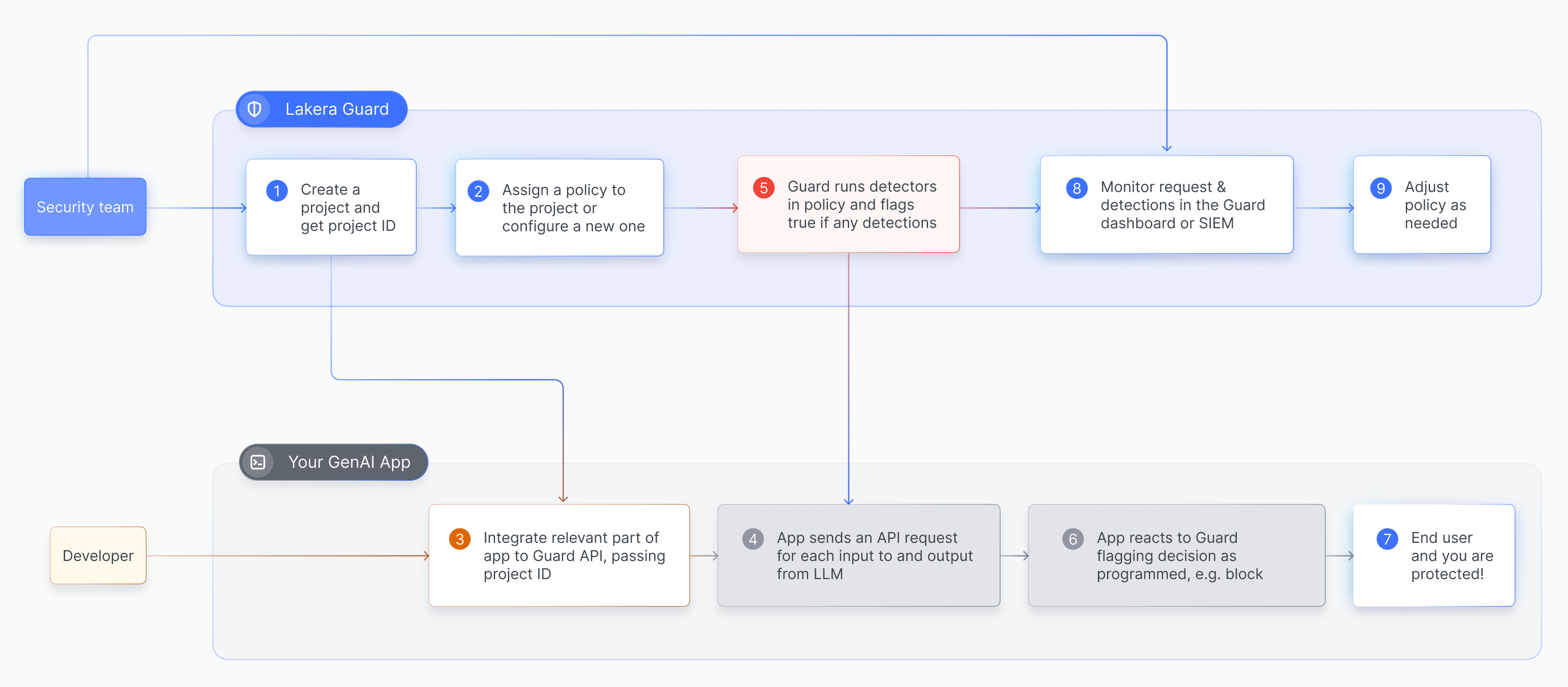
For a quick introduction to integrating the Guard API please see our Developer quickstart.
For technical API reference documentation and an interactive API tester, see /v2/guard.
For comprehensive AI Guardrails integration guidance, see our Integration Guide.
API Endpoint
Flagging Logic
When the detectors specified in the policy are run during a screening request, they will be marked as “flagged” if they detect a threat. If any of the detectors flag then the guard request returns "flagged": true. If none of the detectors flag then the guard request returns "flagged": false.
You can decide within your applications what mitigating action to take to handle flagged responses. See our integration guide here for guidance on handling threats.
Optionally, a breakdown of the flagging decision can be returned in the response by setting "breakdown": true in the request (see here). This will list the detectors that were run, as defined in the policy, whether each of them detected something or not, and the confidence level of each detection result.
Request Best Practices
Flow
It is recommended to call guard for screening every LLM interaction at runtime. The guard screening request should be integrated into the control flow after the LLM response has been generated but before it’s been returned to the end user or downstream. This ensures there are no bad outcomes or damage caused and minimizes added latency.
Optionally, guard can additionally be called when capturing inputs to the LLM for screening threats before LLM processing and if there are risks of data leakage to third-party LLM providers.
See our integration guide here for guidance on choosing your screening flow.
Unique project ID
It is recommended to set up a unique project for each separate integration within each application and environment. This enables you to specify the relevant guardrails via an appropriate policy and flagging sensitivity for each use case and data pattern, as well as separately track each source of threats for follow-up investigations and mitigating actions.
By passing a project_id in a guard request (see here), this specifies the relevant project and determines the policy that will be used for screening that request.
If no project_id is passed in the guard request, then the AI Guardrails Default Policy will be used.
Message Formatting
Always pass clean, original content: Where possible, screen the exact content as received from users and reference documents, without additional system instructions or decorators that may trigger false positives.
Separate system prompts correctly: Pass your system instructions in separate messages with role: "system" to prevent them from being flagged as potential prompt attacks.
Include conversation history: Pass the previous messages in the conversation history to provide context. AI Guardrails will screen the last interaction (the most recent user-assistant exchange or tool invocation) in the list of messages. Previous interactions and system prompts are not screened but may be used as context. AI Guardrails is designed to be called at every interaction and tool call in a session. Earlier messages aren’t directly re-screened as they should have already been screened by previous Guard calls. This prevents issues where a previously-flagged message would continue blocking all subsequent interactions for a user.
Example of correct message structure:
In the example above the last two messages, user and assistant, would be screened as the most recent interaction in the conversation. The other messages would be used as context but not screened directly.
Request metadata
It is recommended to include request-level metadata such as user ID, session ID and user IP address in guard API requests to help identify problematic sessions and malicious users for follow-up investigations and mitigating actions.
For more information please see the metadata documentation.
Reference Documents and RAG Content
When screening RAG applications, include reference documents as additional user messages in the conversation history:
Batch document screening: For static document sets like knowledge bases, screen documents for prompt attack poisoning off-line when they’re added rather than at runtime during each user interaction to reduce latency and costs.
See our integration guide here for guidance on document and RAG screening.
Latency considerations
The latency of the guard API response depends on the length of the content passed for screening, as well as the detectors run according to the policy.
AI Guardrails uses smart chunking and parallelization to reduce latency when screening long content and keep requests under a latency “cap”, regardless of policy or content length.
For SaaS customers, AI Guardrails is deployed globally across data centers to reduce network latency.
Common Integration Issues
False Positive Triggers
The most common GenAI attack pattern is to add instructions that look like system instructions within LLM inputs. This is why it’s important to avoid AI Guardrails screening content that contains benign system instructions, as these are likely to be flagged as attacks as they resemble actual attacks.
Common causes of unnecessary flagging:
- System prompts passed as user content: Separate system prompts and developer instructions into different message roles
- Additional system instructions mixed with user content: Pass clean, original inputs wherever possible or strip out any added system instructions or decorators where possible
- Coding decorators or formatting: Remove before screening or add to allow lists in the policy
- High entropy data: Encoded images, long repeated tokens, or random strings can trigger detections as these resemble common jailbreak components
Gateway Integration Challenges
When integrating AI Guardrails within an AI gateway where clean user inputs aren’t passed or accessible:
- Add input sanitization: Strip known instruction patterns before screening where possible
- Use allow lists: Configure trusted instruction patterns in your policy to prevent flagging of legitimate system instructions
- Work with us to calibrate: With your consent and collaboration, Check Point’s machine learning experts calibrate our detector models to reduce false positives on your specific data patterns
Calibration and Fine-tuning
Expect calibration cycles: Plan for policy optimization and model calibration during your rollout. The more information you can provide us about your use case and false positives, the better Check Point can tune detection performance on your specific data patterns. At production scale, with calibration, customers typically see a false-positive rate below 0.5%; accuracy measured on a small or untuned setup is not representative.
Common rollout approaches:
- Prior analysis: Use the
/guard/resultsendpoint to analyze historical traffic to determine flagging rate and data issues - Monitor first: Integrate AI Guardrails without blocking to establish baseline flagging rates
- Staged rollout: Begin blocking flagged threats with the most lenient sensitivity level, L1, and gradually increase sensitivity to the target risk tolerance
For architectural guidance on rollout strategies, see our Integration Guide.
Advanced Features
Masking using payloads
guard can optionally return a payload listing the string location and type of any PII, profanity, or custom regular expression matches detected. This can then be used by your application to mask sensitive contents before passing to the LLM or returning to the end user.
To do this, pass "payload": true in the request body (see here).
Agent and Tool Integration
For AI agents using tools, include all message roles, including assistant tool_calls, in the conversation flow. The input messages follow the same format as the OpenAI chat completions api. Note that /guard currently only support content type text.
AI Guardrails screens the last interaction in the conversation (in this example, the tool and final assistant messages). The earlier messages provide context but are not actively re-screened. For multi-step agent workflows, call AI Guardrails at each step to ensure each interaction is screened as it occurs.
Roles determine how content is screened: the most recent user content is screened as input and the most recent assistant content as output, system messages are trusted and unscreened, and tool and developer messages are screened as untrusted content. This means prompt attacks and data leakage in tool responses are detected according to your policy, not just in user input. Tool descriptions can also carry injected instructions; screen them by passing the description as content in a Guard API call, for example when a new tool or MCP server is added.
For agent-specific runtime protections — the Off-Task Action detector and the runtime Tool Allow/Deny List — see Agent Behavior Defense.
Screening Streamed LLM Outputs
When your LLM generates streamed responses, you have several options for integrating AI Guardrails screening while balancing safety, latency, and user experience considerations.
Screening Approaches
-
End-of-stream screening: Wait until the full LLM output has been generated, then screen the complete response before displaying it to the user. This provides the most accurate threat detection but introduces the highest latency as users must wait for both generation and screening to complete.
-
Incremental screening: Screen regular snapshots of the streamed output as it’s generated. This allows for earlier threat detection but requires handling the complexity of partial context evaluation.
We recommend sentence-level chunking as this provides better accuracy. Incremental snapshot chunking should be at a minimum of 10 tokens (the longest chunk that could be shown and pulled back before a user has time to process and read it). Longer chunks reduce Guard API usage but increase latency and can delay threat detection.
Response Handling Options
Delay buffer approach (recommended for balanced use cases) Screen content snapshots and confirm there are no threats before displaying the increment to the user. This is the safest option as users never see problematic content, though it introduces additional latency between generation and display. Latency can be minimized through small incremental chunk size. Recommended when security is prioritized over minimal latency.
Pull-back approach Display content to the user as it streams but immediately remove it when a threat is detected. This minimizes latency to first token but creates the possibility of users seeing problematic content briefly, which may be unacceptable. Consider for low-risk use cases where minimal latency is critical.
Handling Mid-Stream False Positives
When using incremental screening, detectors may flag partial content that appears threatening but becomes benign once additional context is provided. Consider this example:
"I like going swimming and shopping with"✅ Pass"I like going swimming and shopping with my family in the big city. Also"✅ Pass"I like going swimming and shopping with my family in the big city. Also when I have spare time I like to kill"❌ Flagged"I like going swimming and shopping with my family in the big city. Also when I have spare time I like to kill time by playing video games at home."✅ Pass with full context
Your application needs to handle these scenarios by either:
- Continuing to screen subsequent chunks and allowing content through if later context clarifies the meaning
- Implementing a hold period when threats are detected midstream before making conclusive flagging decisions
- Accepting some level of false positives in exchange for faster threat detection