Policies
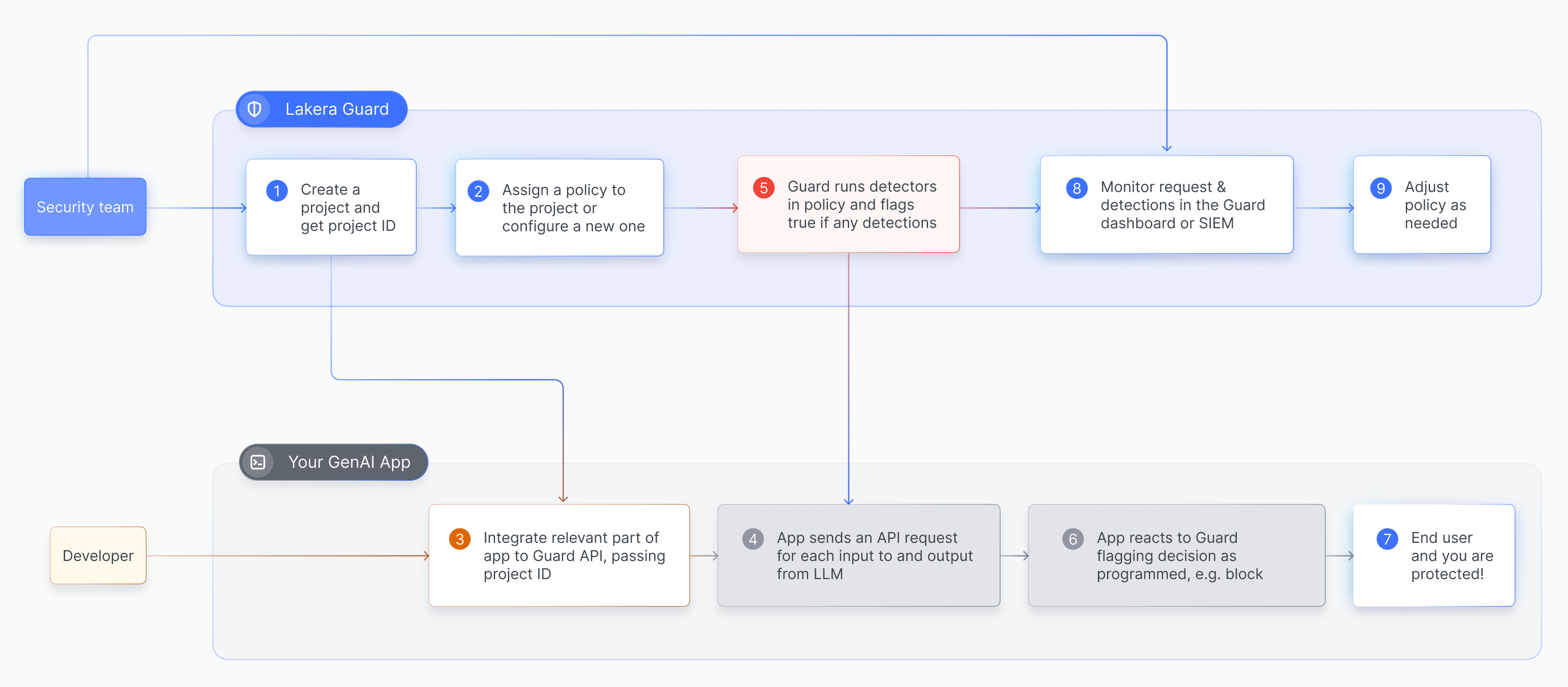
Check Point AI Guardrails can be used to screen LLM interactions for a range of different threats. The configuration of the guardrails that will be applied, the flagging logic, and their strictness are all controlled centrally via an AI Guardrails policy.
Through a policy, you can set up distinct configurations for each application, LLM-based feature, environment, or customer as you like. You can also configure and dynamically update individual apps and integrations’ AI Guardrails detectors and strictness on the fly to respond to threats or user experience issues, or to achieve your desired risk appetite.
Each project in AI Guardrails is assigned to a policy. Multiple projects can share the same policy, allowing you to manage guardrails quickly and consistently across multiple applications, environments, features, and LLM integrations. A project cannot be assigned to multiple policies.
Guardrails
AI Guardrails’ guardrails are organized into five defense categories:
You can read more about Check Point guardrails here.
A policy determines the guardrails to apply when securing LLM interactions, as well as the flagging sensitivity level, so you can fine tune to your use cases and risk tolerance.
How policies work
Each project in AI Guardrails is assigned to a policy configuration. The policy is
set by selecting the defenses you want AI Guardrails to run on every
guard API request that is tagged with the Project ID for that project.
To give some examples, the policy could be to:
- Check user inputs for prompt attacks or any PII.
- Check LLM outputs for content moderation violations or suspicious links from unexpected domains.
- Check tool responses in agent workflows for prompt attacks, tool calls for data leakage and off-task actions, and block calls to tools outside an allow list.
Flagging logic
When the guardrails specified in the policy are applied to a request, if they detect something
they will be marked as having ‘flagged’. If any of the guardrails flag, then the
guard request returns flagged equals true. If none of the guardrails
flag then the guard request returns flagged equals false.
You can decide within your applications what to do with a flagged response. You can choose to block the inputs being passed to the LLM or the LLM output returned to the user. You can trigger a confirmation with the user that they want to proceed. You can do nothing and just log it for analysis and monitoring. AI Guardrails enables you to flexibly handle detected threats and violations.
Optionally, a breakdown of the flagging decision can be returned in the response. This will list the guardrails that were applied, as defined in the policy, whether each of them detected something or not, and the confidence level of each detection result.
Flagging sensitivity
You can fine-tune the sensitivity for flagging by specifying the confidence level threshold for each policy. This enables you to fine-tune the strictness and risk threshold to each of your use cases.
For example, if you had a high risk tolerance for one use case you can set the policy to only flag very high confidence detections in order to have low false positives. Or, if there was a use case you wanted to be really sure wasn’t manipulated, even at the cost of reduced user experience, you could set the policy to flag anything that the guardrails determine could potentially be a detection.
This is done by setting the flagging sensitivity for each policy. This is the level of confidence above which a detector will flag. AI Guardrails uses the following confidence levels:
- L1 - Lenient, very few false positives, if any.
- L2 - Balanced, some false positives.
- L3 - Stricter, expect false positives but very low false negatives.
- L4 - Paranoid, higher false positives but very few false negatives, if any. This is our default confidence threshold.
These levels are in line with OWASP’s paranoia level definitions for WAFs.
The Policy Impact Simulator in the dashboard provides a visual way to compare flagging rates across all sensitivity levels using your historical traffic. See Policy Impact Simulator for details.
Alternatively, the Guard API results endpoint can be used to get the detector confidence
threshold level results of a screening request. This endpoint can be used to analyze
your data to determine the appropriate threshold for a flagging decision for blocking,
for example, or for ongoing detector performance monitoring. It is not intended for the
results endpoint to be used in runtime application decisions, as
this prevents them being controlled or modifiable by policy.
Latency considerations
The latency of the guard API response depends on the length of the content passed for
screening, as well as the detectors used for screening according to the policy.
Note that making changes to a policy may have an impact on the latency experienced by your application and end users.
AI Guardrails applies smart parallelization and chunking to minimize latency impacts. If you need further help aligning your policies to meet strict latency requirements please reach out to support@lakera.ai.
Check Point policy catalog
Recommended policies
Check Point provides a catalog of recommended policies based on our security experts and experience with customers. These can be used out of the box or customized and built on to meet your security requirements.
AI Guardrails Default Policy
Screening requests should always be tagged with a project ID so the appropriate
policy assigned to the project is applied. If no project_id is passed in the request then the AI Guardrails Default Policy is
used as a fallback option.
The AI Guardrails Default Policy screens any content passed with all Check Point managed guardrails (Prompt defense, Content Moderation, PII, Unknown Links), all with the strictest flagging sensitivity of L4. This ensures your GenAI applications are secure by default but it’s important to configure projects and policies in order to avoid a high false positive rate.
Setting up and configuring policies
The process for setting up and configuring policies is different depending on your deployment option. Please read the relevant page for details: