Evaluating AI Guardrails
Evaluating Check Point AI Guardrails properly is essential to ensure it meets your security requirements while maintaining an excellent user experience. This guide outlines our recommended approach to ensure a successful and informative evaluation.
This guide covers the runtime guardrails. If you are evaluating the full AI Agent Security product — agent discovery, risk assessment, and the agent-specific runtime protections — start with the AI Agent Security Evaluation, which uses this guide for the guardrails portion.
What You’ll Validate
A successful AI Guardrails evaluation answers three critical questions:
-
How accurate is threat detection for your use case?
AI Guardrails delivers market-leading accuracy with minimal false positives. You’ll validate this using attack examples, as well as your own (or representative) normal use data, to ensure AI Guardrails correctly identifies threats while avoiding interrupting benign users.
-
Does AI Guardrails meet your performance requirements?
AI Guardrails is optimized for real-time applications with ultra-low latency. You’ll measure response times to confirm AI Guardrails won’t impact your user experience.
-
How seamlessly does AI Guardrails integrate with your applications?
AI Guardrails integrates with any architecture through simple API calls. You’ll test this with your actual applications to validate the integration approach and user experience.
Suggested Evaluation Approach
Phase 1: Attack detection
- Assemble a test dataset of relevant prompt attacks and content violations. To help, here is a list of public Hugging Face datasets
- Collaborate with Check Point experts to determine the right policy for threat coverage
- Use the
/resultsendpoint to measure threat detection accuracy for the attack data
Phase 2: Check benign data
- Either assemble a test dataset of representative benign data for your application, or integrate for in-line testing
- Use the Policy Impact Simulator in the dashboard to visually compare how different sensitivity levels and guardrail combinations would have affected your data
- Alternatively, use the
/resultsendpoint to see detailed threat detection results for your benign data - Work with Check Point technical support to identify any integration issues causing false positives
- Assess what would be flagged at different sensitivity levels and policy combinations
Phase 3: Test real-world accuracy
- Based on the results in phase 2, collaborate with Check Point experts to determine the right policy
- Use the
/guardendpoint with your chosen policy - Use the Policy Impact Simulator to verify your chosen policy configuration against historical traffic before going live
- Measure true/false positive rates on representative data
- Fine-tune policy settings based on results
What you’ll need
- Representative data from your AI application(s) for testing, or quality test data if this is not possible to use
- Clear success criteria for your evaluation
- A designated point person for coordination with Check Point
Avoiding Common Evaluation Pitfalls
Most evaluation issues stem from a few common mistakes. Follow these practices to ensure accurate results:
Data and Integration Best Practices
- Critical: Separate system prompts from user content
The most common cause of false positives is passing system instructions within user message roles. AI Guardrails correctly flags attempts to inject system-like instructions, so ensure your system prompts use the system role and user inputs use the user role.
- Screen original content: Pass the exact untrusted input from the user or external resources. If this isn’t possible, remove any system instructions, UUIDs, or formatting artifacts added during preprocessing before sending to AI Guardrails
- Test holistically: Screen both inputs and outputs together for maximum accuracy
- Use high quality test data: Verify the accuracy and relevance of test data labels. Open source data sets can be inaccurately labeled or include data not relevant for AI security, e.g. biased language.
Use appropriate policies
It’s important to evaluate AI Guardrails for the threats relevant to you and use a policy during testing that captures your requirements.
- Use representative policies: Evaluate with Check Point’s recommended policies or a suitable custom policy, rather than the default strictest policy
- Consider sensitivity levels: Policies range from L1 (lenient) to L4 (strict) - start lenient and adjust based on your risk tolerance
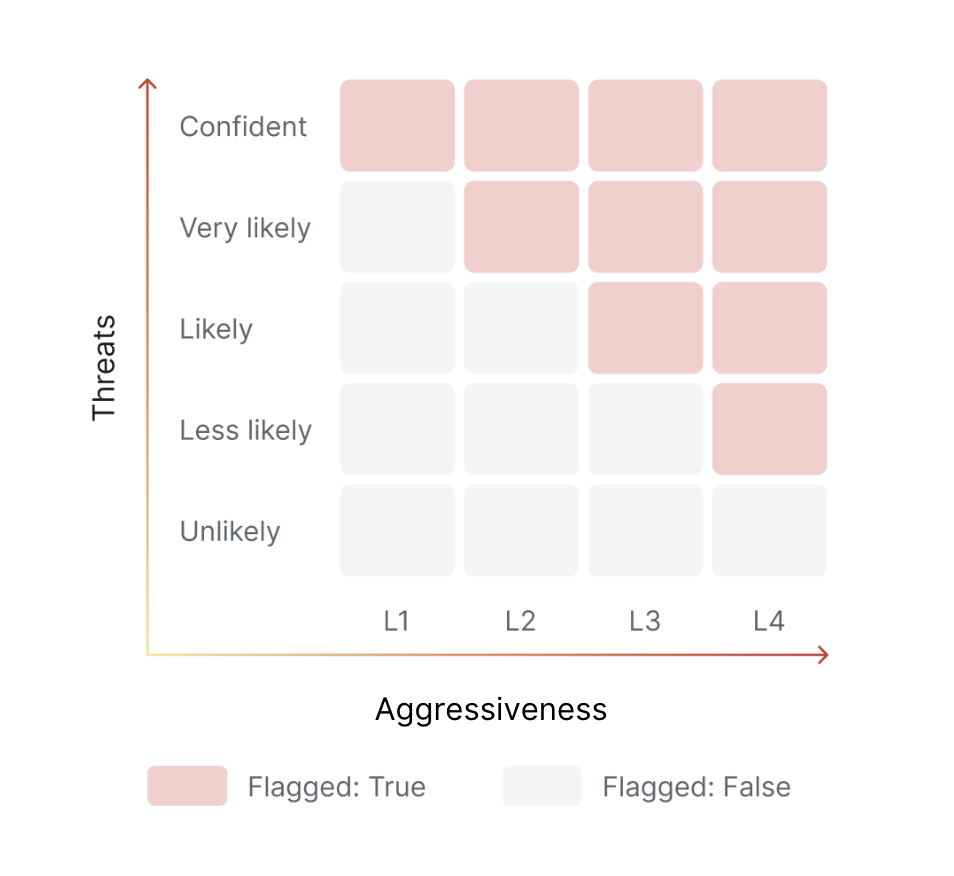
- Match your policy to your test data: Offensive or dangerous user input like “How to build a bomb?” aren’t prompt attacks by themselves - they’re inappropriate content. If testing harmful content scenarios, ensure your policy includes Content Moderation alongside Prompt Defense.
What Success Looks Like
A successful evaluation typically achieves:
- False positive rate: ~0.1% on your production data
- Latency: <150ms for typical requests with persistent connections
- Integration effort: Hours, not days, to implement
- Coverage: Comprehensive protection across all relevant threat types
Latency reference figures
Response latency depends on both the content length and the number of detectors run by the policy, so reference figures are only meaningful with those conditions attached. Documented p95 latency for the v2 Guard API:
When comparing your own measurements against these figures, run them with the policy you intend to use in production and state the content length and detector count alongside the numbers.
Evaluation timeline
Static dateset evaluations can be completed in less than a week. End-to-end evaluations can be completed within 2-4 weeks, including development time.
Need Help?
Our team provides hands-on evaluation support including:
- Evaluation datasets
- Custom policy recommendations for your use case
- Technical integration guidance
- Performance optimization advice
- Detailed evaluation frameworks and scripts
Contact our team to discuss your evaluation requirements.