AI Guardrails Integration Guide
Check Point AI Guardrails functions as a control layer around models, assistants, or agents. Whether deployed as a self-hosted container or leveraged via the SaaS service, AI Guardrails fits seamlessly into a wide range of use cases and architectures.
AI Guardrails delivers industry-leading accuracy with minimal latency impact, enabling robust AI security without compromising user experience or application performance.
This guide helps solution architects, security teams, and AI product teams make strategic decisions about integrating AI Guardrails into their systems.
For technical implementation details and recommendations in order to avoid common pitfalls, see the Guard API Documentation.
Key Integration Decisions
1. Choosing Your Screening Flow
AI Guardrails provides the most accurate and comprehensive protection when screening interactions holistically with full context. We recommend screening the complete interaction (all inputs and outputs together) after the LLM response but before showing content to users or sending it downstream.
This approach offers:
- Single API call efficiency: One screening request per interaction reduces latency and costs
- Complete context: Full conversation and response context enables the most accurate threat detection
- Damage prevention: Block threats before any harmful content reaches users or downstream systems
- Future-ready architecture: Adding new guardrails requires only policy changes, not redevelopment
Alternative approaches for specific requirements:
Additional input screening: Some customers additionally screen inputs separately before LLM processing to:
- Avoid LLM costs on flagged inputs
- Prevent sensitive data from reaching third-party LLM providers
Note that this adds latency to the user experience
Parallel input screening: For customers focused primarily on input screening, processing can be done in parallel with LLM inference since AI Guardrails typically completes screening before LLM processing finishes. However, this approach limits future expansion to output screening capabilities.
Recommended integration approach: Always include outputs in your screening flow, even if you initially only configure policies for input threats. This ensures you can easily expand protection coverage through policy updates rather than requiring architectural changes.
2. When to Screen Content
Runtime screening is essential for dynamic interactions and should be implemented at every stage where content flows through your system:
- User interactions: Screen all user inputs and LLM responses in real-time
- Reference content: Any untrusted input can contain prompt attacks so it’s vital to screen all documents, web pages, reference data, or anything else provided to the LLM as context
- Agent workflows: Screen each step of multi-turn agent interactions to prevent harmful outputs at any stage
- Dynamic content: Screen any content that changes based on user input or external data
Batch/offline screening complements runtime protection for static content:
- Knowledge base documents: Screen documents when uploading to identify data poisoning or sensitive information
- Template libraries: Validate content templates and standard responses
- Historical analysis: Audit past interactions for compliance or threat intelligence
Post-hoc screening and monitoring: AI Guardrails supports analysis and monitoring use cases where runtime protection isn’t required:
- Compliance reporting: Analyze interactions for regulatory documentation
- Threat research: Identify attack patterns and trends in your applications
- Performance analysis: Understand content patterns and policy effectiveness for policy fine tuning
Note that AI Guardrails offers a specific results endpoint to support analysis.
3. How to Handle Threats
AI Guardrails is deliberately designed to provide flexible threat detection while allowing customers to implement their own response logic. AI Guardrails provides a boolean flagging response and optional detailed breakdowns - your application determines the appropriate action.
Common response patterns:
Blocking with appropriate messaging: Prevent flagged content from proceeding, but tailor user communication to the situation:
- Don’t reveal attack detection to potential bad actors
- Provide helpful guidance when users inadvertently trigger content or data leakage policies
- Offer clear paths forward for legitimate use cases
Progressive response: Different threat types may warrant different responses:
- High-confidence threats: Immediate blocking
- Policy violations: User confirmation or override options, where appropriate. Or logging and monitoring without blocking for low risk situations
- Data leakage: Warn the user if sensitive data is found in inputs and prevent egress if found in LLM outputs. You can also choose to mask sensitive data
Monitoring and alerting: Track threats without immediate blocking:
- Security team notifications for potential threats
- Flagging behavior analysis for policy optimization
- Compliance documentation and audit trails
AI Guardrails’ flexibility enables you to balance security requirements with user experience considerations specific to your application and user base.
4. Rollout Strategy
Analyze-first approach: Begin with AI Guardrails in monitoring mode, or perform historic analysis, to establish baselines, tune policies, and collaborate with Check Point for calibration before enforcement. This approach minimizes user impact while building confidence in detection accuracy.
Calibration: Around 6000 representative data points typically provides sufficient data for detector and policy calibration and false positive reduction.
Graduated enforcement: Implement blocking for high-confidence detections first, then gradually expand coverage as policies are refined.
Full enforcement: For high-security applications, blocking can be implemented immediately with acceptance of an initial calibration period.
Architecture Patterns
Chat Application Pattern
Most suitable for conversational interfaces, customer support bots, and interactive AI assistants.
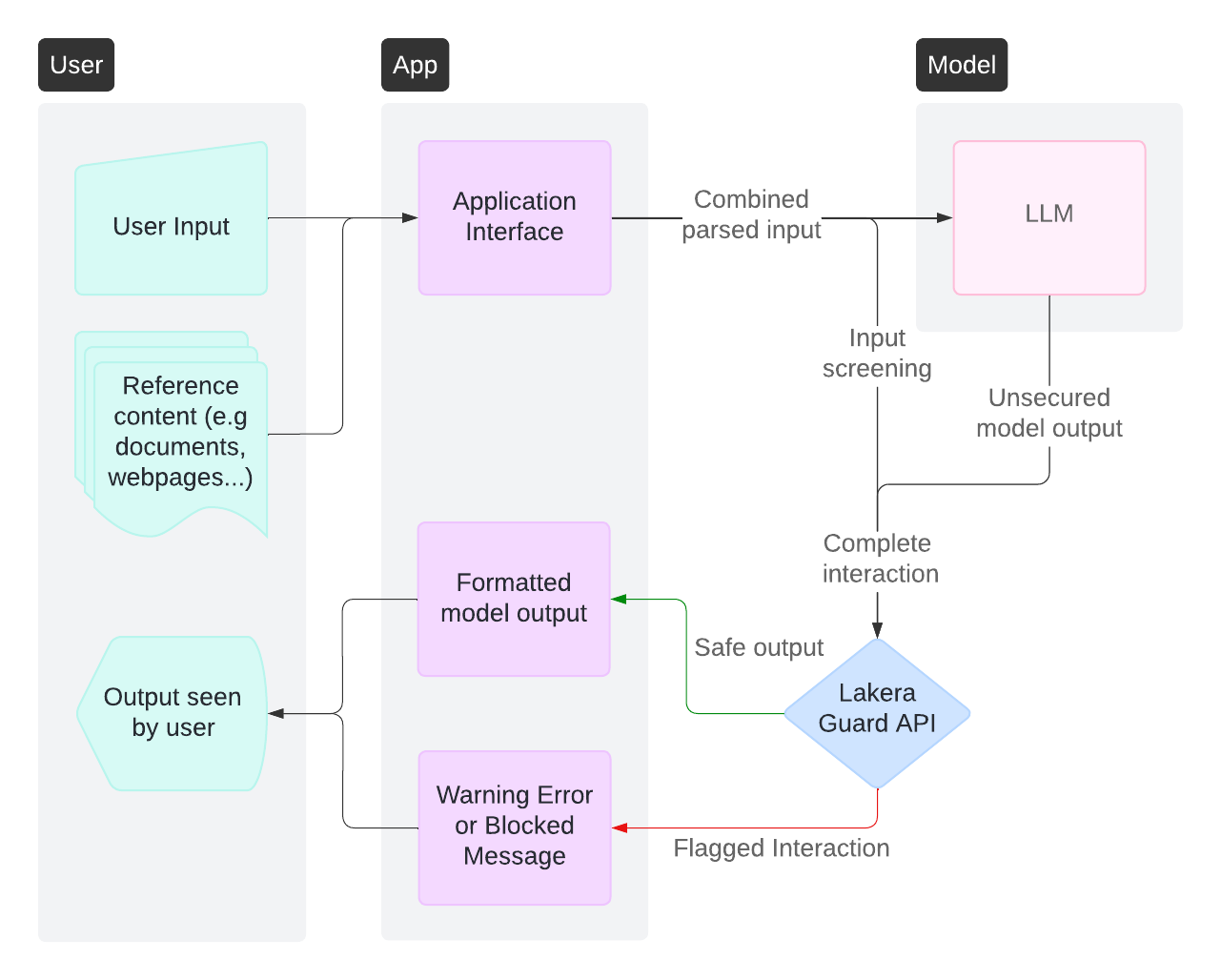
Recommended approach: Holistic screening after LLM response
- Screen the complete interaction (input + output) in a single API call
- Implement user-friendly responses for flagged content
- Include conversation history for context; AI Guardrails screens the last interaction (earlier messages should be screened at each step)
Key considerations:
- AI Guardrails’ low latency ensures minimal impact on response times
- Industry-leading accuracy reduces false positive concerns
- Comprehensive threat coverage without architectural complexity
- Optional additional screening and response flow of inputs before LLM processing
Document Processing Pattern
Designed for RAG systems, knowledge management, and content analysis workflows.
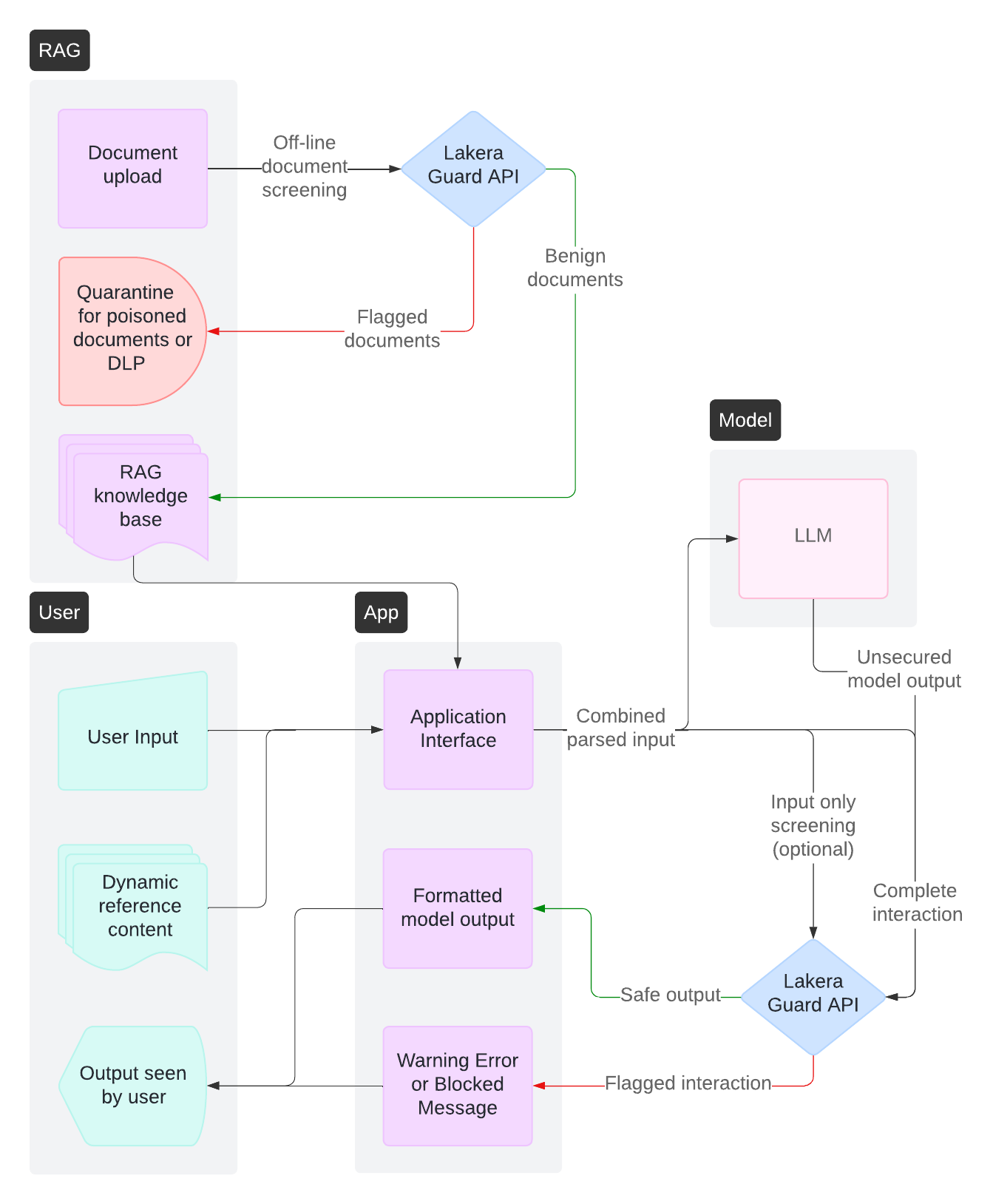
Recommended approach: Hybrid screening with offline preprocessing
- Screen static documents during upload/ingestion for prompt attack poisoning and sensitive data
- Screen dynamic user queries and LLM responses at runtime
- Leverage AI Guardrails’ large context window and smart internal chunking
Key considerations:
- Batch processing enables efficient screening of large document volumes
- Runtime screening maintains protection for dynamic interactions
- Document versioning supports ongoing content management
AI Gateway Pattern
Centralizes AI security monitoring and enforcement across multiple applications and teams within an organization.
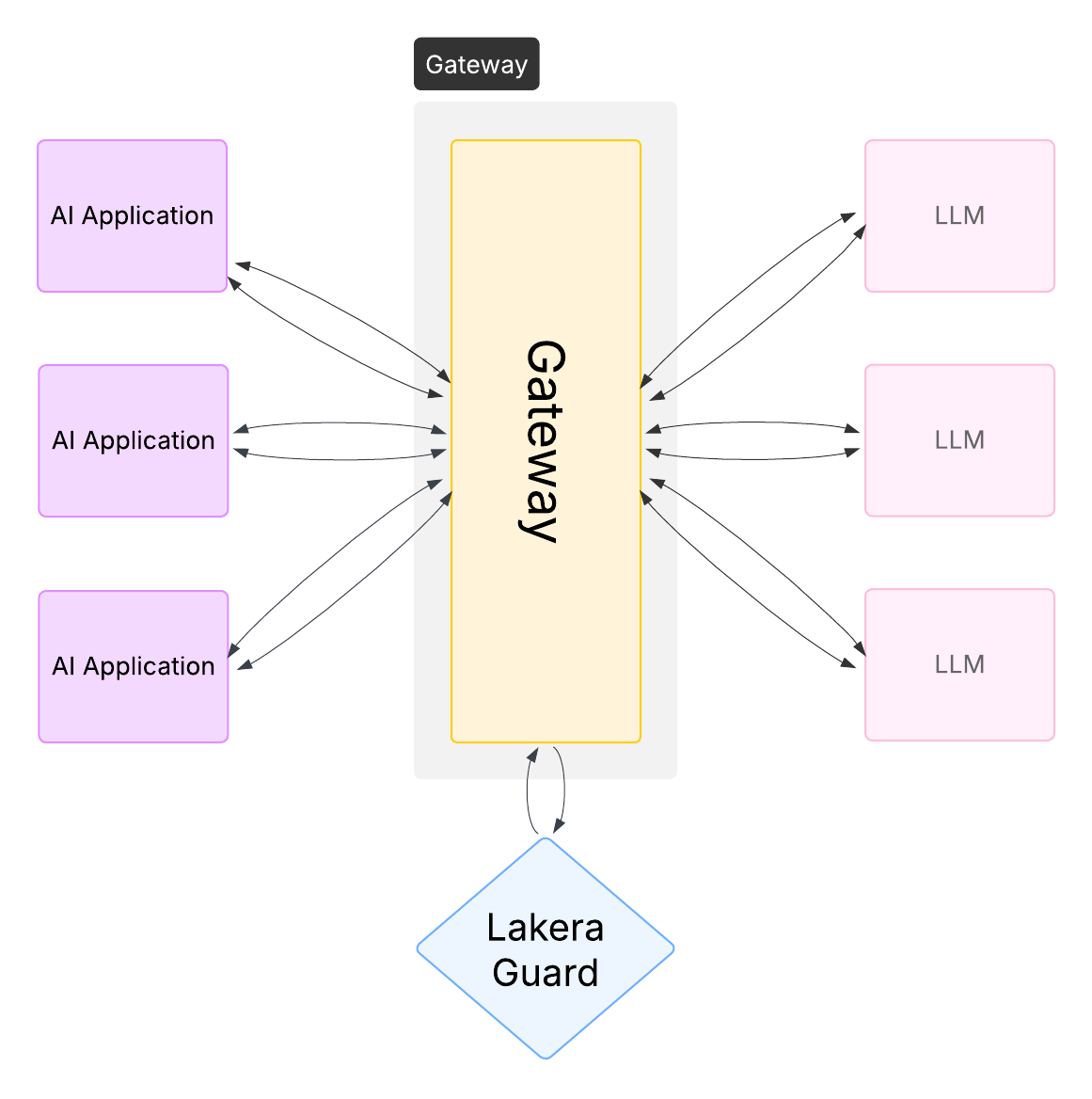
Recommended approach: Centralized screening with application-specific policies
- Implement AI Guardrails at the gateway level for consistent security across your organization
- Use project-based policies for different applications and environments
- Provide observability across all AI interactions across your organization
Key considerations:
- Gateway integration enables organization-wide security standards
- Use case-specific policies support varying risk requirements
- Centralized monitoring provides comprehensive threat visibility
- No-code enforcement controls ease the roll out of security across applications
Agent and Workflow Pattern
Supports AI agents using tools, multi-step workflows, and autonomous systems.
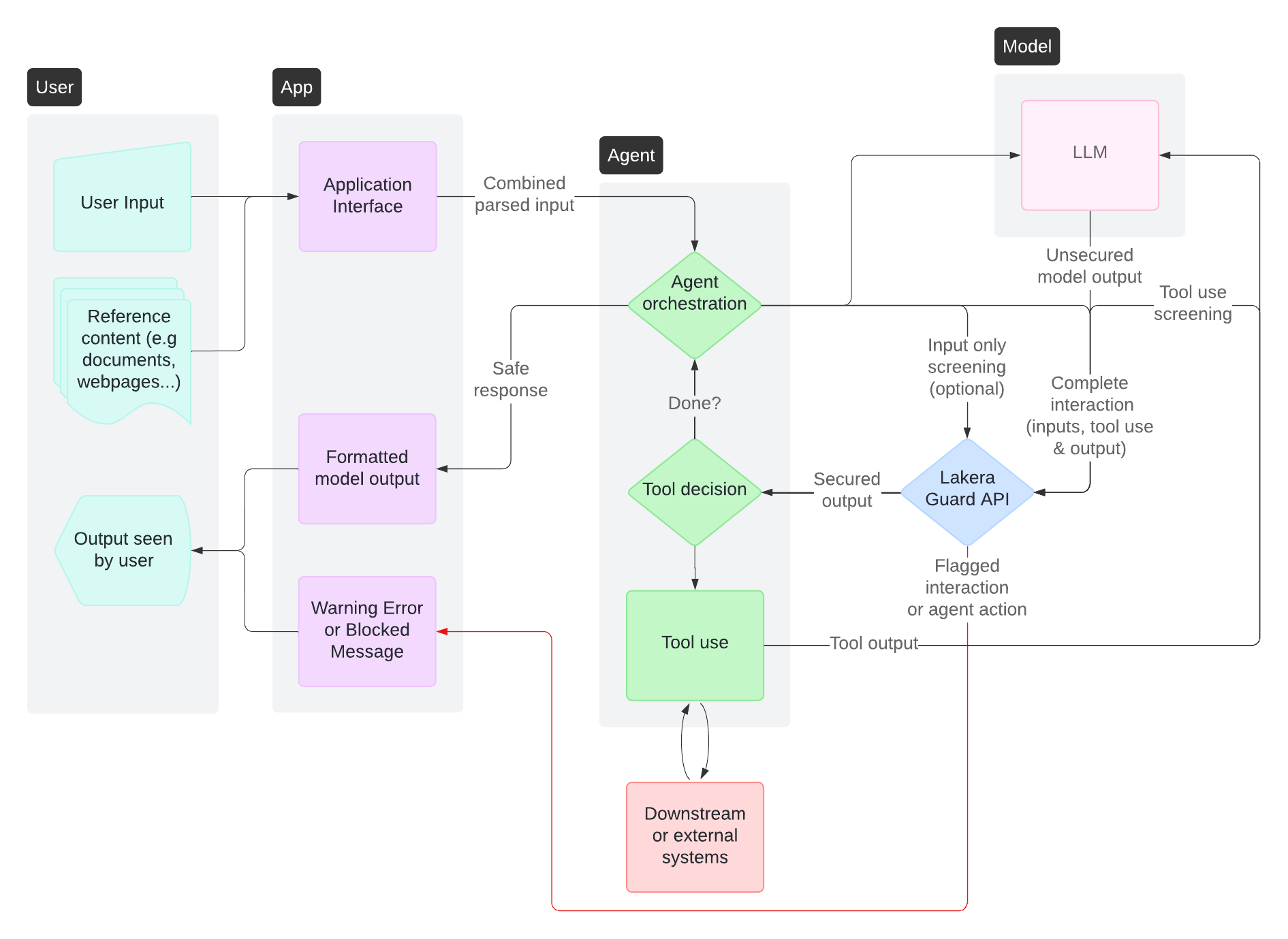
Recommended approach: Contextual screening across agent interactions
- Screen each step and loop of agent workflows to prevent prompt attacks and harmful outputs at any stage
- Block suspicious tool actions before they take place to prevent damage via downstream or external systems
- Include all message types (user, assistant, tool, developer) in screening
- Screen both tool inputs and outputs for comprehensive coverage
Key considerations:
- The impact of prompt attacks and data leakage can be greater with agents due to their tool use and connections to other internal or external systems
- Agent workflows may involve multiple LLM interactions requiring screening at each step
- Tool use responses may introduce indirect prompt attacks and unexpected or malicious content requiring validation
- For agent-specific runtime controls — the Off-Task Action detector and the runtime Tool Allow/Deny List — see Agent Behavior Defense
Next Steps
- Implementation: Review the Guard API Documentation for specific implementation details and advice to avoid common pitfalls
- Quick Start: Try the Developer Quickstart for hands-on experience
- Policy Configuration: Learn about Policies and Projects for customization
- Calibration Planning: Contact support@lakera.ai for architectural guidance and collaborative policy and detector optimization